- Java并发容器有哪些 concurrentHashmap: 线程安全的HashMap, Node数组+链表 + 红黑树
- ArrayBlockingQueue和LinkedBlockingQueue的实现原理 ArrayBlockingQueue是object数组实现的线程安全的有界阻塞队列
LinkedBlockingQueue是一个单向链表实现的阻塞队列
PriorityBlockingQueue
SynchronousQueue
Executors.newCachedThreadPool() 使用的SynchronousQueue, 实际就不想往队列里放元素,就是想有多少任务就生成多少线程去做。线程拉满,不做任务堆积。 但newCachedThreadPool(). maxThreadSize 是Integer.MAX_VALUE, 容易内存溢出。
白话
为什么ArrayBlockingQueue是一个ReentrantLock,LinkedBlockingQueue是两个?
- 阻塞队列原理 核心思想就是,何时阻塞:空不让你取,满不让你加。
- 谈谈对ConcurrentHashMap的了解 1.7 结构: 分段的数组+链表;
1.8 结构: Node数组+链表 + 红黑树;
get是怎么做的
hash。 hashcode高低16位异或得到hash值,(h ^ h >>> 16) & 2147483647;
桶位节点就是要找节点,直接返回该节点
如果节点hash值小于0,说明是已迁移的节点或者红黑树bin,调用node.find(), TreeBin 和 ForwardingNode 都继承Node重写find方法
剩下情况就是链表,遍历判断是否节点存在
注:ForwordingNode的hash值为-1,红黑树的根结点的hash值为-2。 TreeBin 和 ForwardingNode 都继承Node重写find方法
put是怎么做的
hash。 hashcode高低16位异或得到hash值,(h ^ h >>> 16) & 2147483647;
桶位为空,cas设置新node,U.compareAndSetObject
如果hash值为-1,则helpTransfer,else 加synchronized锁住头结点,判断是树,调用添加到树中方法,如果是链表,添加到尾端。
判断是否到了8个,链表变树; 判断size是否到了阈值,触发扩容。size总数增加cas (U.compareAndSetLong)
resize是怎么做的
newTable, 大小是旧表的2倍
头结点加锁,不允许其他线程更改,但可get,
判断桶中各节点位置,复制一模一样的节点到新表(非直接移过去,还要get),到新表可能在旧桶位也可能在新桶位
分配结束之后将头结点设置为fwd节点(指向新表)
白话:线程安全的map。1.7版本是使用分段锁实现的线程安全,segment上加锁,在构建的时候可以设置大小,默认是16,就是并发度默认只有16. 1.8版本的线程安全是用synchronized+cas实现的,使用synchronized锁住链表或红黑树的头结点,使用cas来进行size++和首个节点入桶。1.8的并发度是随着桶位增加而增加的,所以并发效率会随扩容提升很多倍。
- 谈谈对Java内存模型的了解 总结:
jmm是为了解决线程间通信问题,线程间通信通常有两种解决方法,共享内存或通知机制, jmm使用了共享内存的方式。
- volatile原理
volatile的特征
Volatile的内存语义
Volatile的重排序
白话:volatile有两个特性,可见性和禁止指令重排序。可见性,当一个线程更新volatile变量后,这个变量会立即写入到主内存中,其他线程读取时会从主内存中读取最新的值。禁止指令重排序,两个对volatile变量的操作不能被重排序,底层是通过内存屏障实现的。
- java的乐观锁CAS锁原理 CAS英文全称Compare and Swap,直白翻译过来即比较并交换,是一种无锁算法,在不使用锁即没有线程阻塞下实现多线程之间的变量同步,基于处理器的读-改-写原子指令来操作数据,可以保证数据在并发操作下的一致性。
CAS包含三个操作数:内存位置V,预期值A,写入的新值B。在执行数据操作时,当且仅当V的值等于A时,CAS才会通过原子操作方式用新值B来更新V的值(无论操作是否成功都会返回)。
CAS的含义是:我认为V的值应该为A,如果是,那么将V的值更新为B,否则不修改并告诉V的值实际为多少
CAS是怎么获取到预期值的? 通过unsafe类获取到的
1 2 3 4 5 6 7 8 public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); return var5; }
CAS修改的值为什么要是volatile? 可见性
在compareAndSet的操作中,JNI借助CPU指令完成的,属于原子操作,保证多个线程在执行过程中看到同一个变量的修改值
CAS问题:
白话:CAS是Compare and Swap,比较并交换,是一种乐观锁实现线程安全的方式,更加轻量。底层是通过cpu的原子指令实现的比较并替换。使用的时候参数有内存位置,预期值,写入的新值,当通过内存位置拿到的值和预期值相等时,就用新值进行替换,整个操作是原子的,cpu指令保证。
- sychronized使用及原理
修饰实例方法:作用于当前对象实例加锁,进入同步代码前要获得 当前对象实例的锁
修饰静态方法: 也就是给当前类加锁,会作用于类的所有对象实例 ,进入同步代码前要获得 当前 class 的锁。
修饰代码块: 对应的锁则是,传入的synchoronzed的对象实例。
synchronized原理
其中有两个队列 _EntryList和 _WaitSet,它们是用来保存ObjectMonitor对象列表, _owner指向持有ObjectMonitor对象的线程。
上面说到synchronized使用的锁都放在对象头里,大概指的就是Mark Word中指向互斥量的指针指向的monitor对象内存地址了。
白话:
- 锁升级 偏向锁 通过对比Mark Word里存储的锁偏向的线程ID解决加锁问题,避免执行CAS操作。轻量级锁 是通过用CAS操作和自旋来解决加锁问题,避免线程阻塞和唤醒而影响性能。轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令即可。
先在栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝
拷贝对象头中的Mark Word复制到锁记录中。拷贝成功后,虚拟机将使用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针,并将Lock Record里的owner指针指向对象的Mark Word。
如果这个更新动作成功了,那么这个线程就拥有了该对象的锁,并且对象Mark Word的锁标志位设置为“00”,表示此对象处于轻量级锁定状态。
重量级锁* 是将除了拥有锁的线程以外的线程都阻塞。依赖操作系统的metex lock, 存在用户态和内核态切换,消耗较大。
- sychronized缺点
效率低:锁的释放情况少,试图获得锁时不能设定超时,不能中断一个正在试图获得所得线程。
使用synchroinzed修饰一个代码块时,如果一个线程获取了对应的锁,并执行改代码块,其他线程只能一直等待。等待获取锁的线程释放锁,但是获取锁的线程执行释放锁只有2种方式(要么是执行完该代码块,正常释放。要么是.线程执行发生异常,JVM自动释放)一旦这个锁被别人获取,如果我还想获取,那么我只能选择等待或阻塞,只得到别的线程释放,如果别人永远不释放锁,那我只能永远等待下去。不能设定超时等待,无法做到响应中断。
不够灵活(多个线程只是做读写操作,线程直接就发生冲突。)
非公平。使用synchroinzd,非公平锁使一些线程处于饥饿状态,对于一些线程,可能长期无法抢占到锁。对于某些特定的业务,必须使用公平锁,这时synchronized无法满足要求
无法知道是否成功获取到锁
白话:
无有限等待。没有tryLock(带时间参数)
不可中断。没有lockInterruptibly(调用后一直阻塞到获得锁 但是接受中断信号)
读写锁不分离。没有读写锁,读读固定互斥,影响并发
不支持公平锁。
获取锁无返回值。无法知道线程当前有没有成功获得到锁,没有tryLock的返回值
无多路通知机制。lock.condition
- sychronized reentranlock 的区别
有限等待:需要有一种机制可以不让等待的线程一直无期限地等待下去(比如只等待一定的时间或者能够响应中断),这个是synchronized无法办到,Lock可以办到,由tryLock(带时间参数)实现;
可中断:使用synchronized时,等待的线程会一直阻塞,一直等待下去,不能够响应中断,而Lock锁机制可以让等待锁的线程响应中断,由lockInterruptibly()实现;
有返回值:需要一种机制可以知道线程有没有成功获得到锁,这个是synchronized无法办到,Lock可以办到,由tryLock()方式实现;
公平锁:synchronized中的锁是非公平锁,ReentrantLock默认情况下也是非公平锁,但可以通过构造方法ReentrantLock(true)来要求使用公平锁(底层由Condition的等待队列实现)。
读写分离,提高多个线程读操作并发效率:需要一种机制来使得多个线程都只是进行读操作时,线程之间不会发生冲突,这个是synchronized无法办到,Lock可以办到。
可实现选择性多路通知(锁可以绑定多个条件)
- sychronized 和 valotile 的区别
作用范围。volatile更轻量,性能更好,但volatile只能用于变量而synchronized关键字可以修饰方法以及代码块
是否阻塞。多线程访问volatile关键字不会发生阻塞,而synchronized关键字可能会发生阻塞
是否保证原子性。volatile关键字能保证数据的可见性,但不能保证数据的原子性 (eg: i++).synchronized关键字两者都能保证
是否保证同步。volatile关键字主要用于解决变量在多个线程之间的可见性,而 synchronized关键字解决的是多个线程之间访问资源的同步性
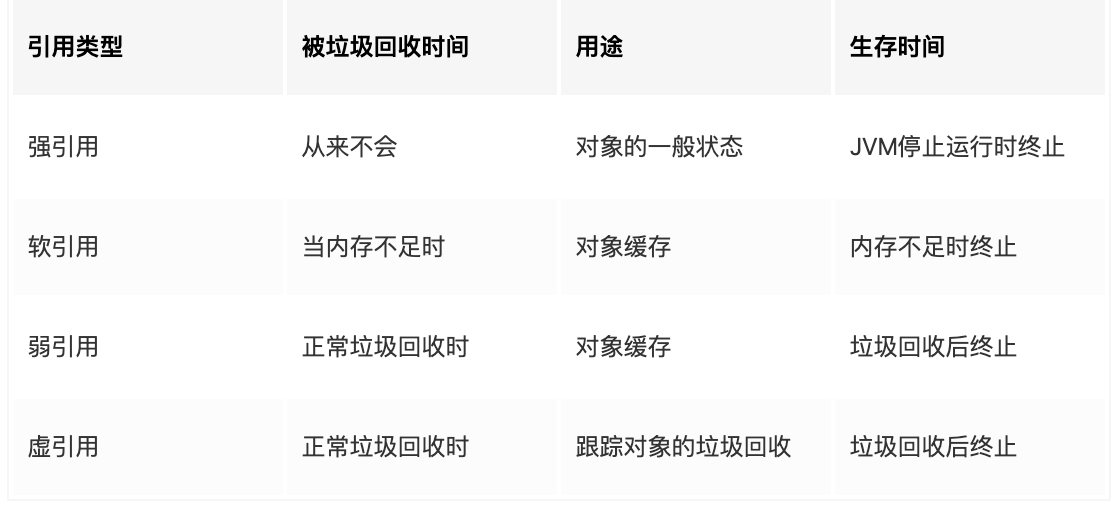
- 弱引用 强引用
弱引用的出现就是为了垃圾回收服务的。它引用一个对象,但是并不阻止该对象被回收。
- ThreadLocal原理 用多线程多份数据,来避免线程不安全
每个Thread 维护一个 ThreadLocalMap 映射表,这个映射表的 key是 ThreadLocal 实例本身,value 是真正需要存储的 Object。也就是说 ThreadLocal 本身并不存储值,它只是作为一个 key 来让线程从 ThreadLocalMap 获取 value。
由于每一条线程均含有各自私有的ThreadLocalMap容器,这些容器相互独立互不影响,因此不会存在线程安全性问题,从而也无需使用同步机制来保证多条线程访问容器的互斥性。
ThreadLocalMap 是使用 ThreadLocal 的弱引用作为 Key的,弱引用的对象在 GC 时会被回收。
为什么选择弱引用?
内存泄漏问题
解决办法:
ThreadLocal最佳实践
- AQS同步器原理?tryAcquire的过程? **AQS使用一个volatile的int类型的成员变量来表示同步状态,通过内置的FIFO队列来完成资源获取的排队工作。AQS通过CAS完成对state值的修改
核心思想是,如果被请求的共享资源空闲,将当前请求资源的线程设置为有效的工作线程,将共享资源设置为锁定状态;如果共享资源被占用,将暂时获取不到锁的线程加入到队列中, 需要一定的阻塞等待唤醒机制机制来保证锁分配。这个机制主要用的是CLH队列实现的**
AQS是通过将每条请求共享资源的线程封装成一个节点来实现锁的分配。通过简单的几行代码就能实现同步功能,这就是AQS的强大之处。
自定义同步器实现的相关方法也只是为了通过修改State字段来实现多线程的独占模式或者共享模式。自定义同步器需要实现以下方法(ReentrantLock需要实现的方法如下,并不是全部):
ReentrantLock这类自定义同步器自己实现了获取锁和释放锁的方式,而其余的等待队列的处理、线程中断等功能,异常与性能处理,还有并发优化等细节工作,都是由AQS统一提供,这也是AQS的强大所在。对同步器这类应用层来说,AQS屏蔽了底层的,同步器只需要设计自己的加锁和解锁逻辑即可
一般来说,自定义同步器要么是独占方式,要么是共享方式,它们也只需实现tryAcquire-tryRelease、tryAcquireShared-tryReleaseShared中的一种即可。AQS也支持自定义同步器同时实现独占和共享两种方式,如ReentrantReadWriteLock。ReentrantLock是独占锁,所以实现了tryAcquire-tryRelease。
独占与共享最大不同就在各自的tryacquire里,对于独占来说只有true或false,只有一个线程得以执行任务;而对于共享锁的tryAcquireShared来说,线程数没达到限制都可以直接执行。
应用:
白话:AQS是jdk提供的一个同步器,可以很方便的生成自定义同步器。AQS内部使用一个volatile的state来表示同步状态,通过一个FIFO队列来做多线程获取资源的排队操作,AQS通过CAS来做state变量的修改。实现AQS只要实现其中判断获取锁和释放锁的方法即可,AQS内部会去做队列入队出队等复杂逻辑处理。使用AQS实现的同步器有ReentrantLock,Semaphore,CountDownLatch。
- CountDownLatch、Semaphore、CyclicBarrier含义及实现原理 CountDownLatch
典型应用场景
开始执行前等待n个线程完成各自任务:例如有一个任务想要往下执行,但必须要等到其他任务执行完毕后才可以继续往下执行。假如这个想要继续往下执行的任务调用一个CountDownLatch对象的await()方法,其他的任务执行完自己的任务后调用同一个CountDownLatch对象上的countDown()方法,这个调用await()方法的任务将一直阻塞等待,直到这个CountDownLatch对象的计数值减到0为止。
CyclicBarrier
CyclicBarrier和CountDownLatch的异同
个人理解:
CountDownLatch 是当前线程等着别人做好再开始做。像做饭一样,买好菜。
Semaphore 是多个线程去获取,有的话就有,没有就等着。 像买房摇号。
CyclicBarrier 是各个线程都达到某个预设点的时候, 可以执行一段逻辑,然后打开所有线程的限制。 像赛马.
java异步 - Callable、Future、FutureTask、CompletableFuture分别是什么 Callable是一个接口,提供一个回调方法,可以放到executorService中
Future接口提供了三种功能:
FutureTask
listenableFuture
CompletableFuture
线程池 - 线程池的创建使用、有哪些参数 为什么要用线程池?
如何创建线程池
- 线程池的原理
先讲构造参数
再描述提交任务后的执行过程
提交一个任务,线程池里存活的核心线程数小于线程数corePoolSize时,线程池会创建一个核心线程去处理提交的任务。
如果线程池核心线程数已满,即线程数已经等于corePoolSize,一个新提交的任务,会被放进任务队列workQueue排队等待执行。
当线程池里面存活的线程数已经等于corePoolSize了,并且任务队列workQueue也满,判断线程数是否达到maximumPoolSize,即最大线程数是否已满,如果没到达,创建一个非核心线程执行提交的任务。
如果当前的线程数达到了maximumPoolSize,还有新的任务过来的话,直接采用拒绝策略处理。
四种拒绝策略
AbortPolicy(抛出一个异常,默认的)
如何自定义拒绝策略:实现RejectedExecutionHandler接口,实现rejectedExecution方法
- 怎么配置参数 线程数:
如果是CPU密集型应用,则线程池大小设置为N+1
如果是IO密集型应用,则线程池大小设置为2N+1
系统负载: 一个进程或线程正在被cpu执行或等待被cpu执行,则系统负载+1, 单核cpu负载小于1表示cpu可以在线程不等待的情况下处理完
IO密集:通常指网络IO