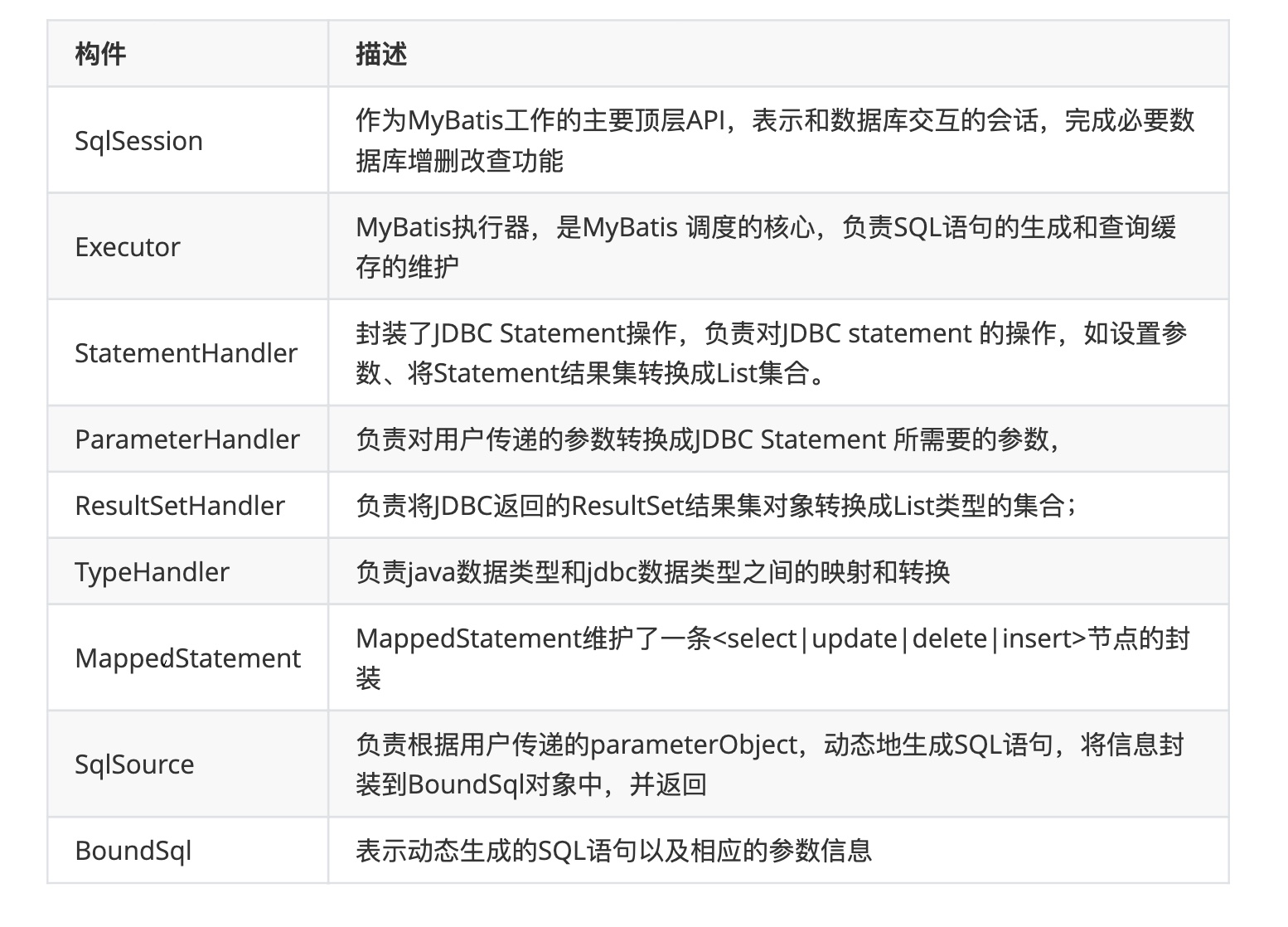
- 什么情况下索引失效#
- 不符合联合最左匹配

- like前导模糊查询 (可以通过 REVERSE()函数来创建一个函数索引解决)
- 字段类型不匹配
- 索引字段施加函数
- or的多个字段都要索引(只要有一个没有索引,就无法使用索引)
- != , <> is null, is not null, not in都会使索引失效
- 索引情况不好(索引列数据区分度太小,例如性别列),范围太大,扫表.
- InnoDB 支持的索引类型#
- B+树索引:
- 全文索引:就是倒排索引
仅能再char、varchar、text类型的列上面创建全文索引
但是面对高级的搜索还是略显简陋,且性能问题也是担忧。 - 哈希索引:
哈希索引在InnoDB中只是一种系统自动优化的功能
Hash 索引仅仅能满足”=”,”IN”和”<>”查询,不能使用范围查询。
Hash 索引无法被用来避免数据的排序操作。
在MySQL运行的过程中,如果InnoDB发现,有很多SQL存在这类很长的寻路,并且有很多SQL会命中相同的页面(page),InnoDB会在自己的内存缓冲区(Buffer)里,开辟一块区域,建立自适应哈希所有AHI,以加速查询。InnoDB的自使用哈希索引,更像“索引的索引”
- innodb 锁#
- 平时怎么创建索引的#
选择区分度高的列做索引
根据查询场景、查询语句的查询条件设计索引
如果要为多列去创建索引,遵循最左匹配原则使用联合索引去创建
在长字符类型的字段上使用前缀索引,减少空间占用
扩展索引的时候尽量做追加,不是新建
- B+树和 B 树的区别,和红黑树的区别#
为什么不用B树?:
因为B树的所有节点都是包含键和值的,这就导致了每个几点可以存储的内容就变少了,出度就少了,树的高度会增高,查询的 时候磁盘I/O会增多,影响性能。由于B+Tree内节点去掉了data域,因此可以拥有更大的出度,拥有更好的性能。
和红黑树:
B+树跟红黑树不用比,B+树的高很低,红黑树比不了。
- 如何优化sql#
- 让sql使用索引,如果查看sql使用索引情况,explain查看执行计划
通过explain命令可以得到下面这些信息: 表的读取顺序,数据读取操作的操作类型哪些索引可以使用哪些索引被实际使用,表之间的引用,每张表有多少行被优化器查询等信息。 rows是核心指标,绝大部分rows小的语句执行一定很快。
Extra字段几种需要优化的情况
Using filesort 需要优化,MYSQL需要进行额外的步骤来对返回的行排序。
Using temporary需要优化,发生这种情况一般都是需要进行优化的。mysql需要创建一张临时表用来处理此类查询
Using where 表示 MySQL 服务器从存储引擎收到行后再进行“后过滤” - 如果让sql使用到索引(符合建索引的几个原则)
- 最左前缀匹配原则
- 选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*)
- 索引列不能参与计算,保持列“干净”, 原因很简单,b+树中存的都是数据表中的字段值
- 尽量的扩展索引,不要新建索引
- =和in可以乱序
- 什么是覆盖索引#
覆盖索引就是把要查询出的列和索引是对应的,不做回表操作
- 为什么尽量不要用select *?#
- 返回了太多不需要的数据
- 无法覆盖索引(select * 走的是聚簇索引),需要回表
- 一个好的应用程序设计应当能够在 sql 中有准确的定义,从而减少歧义或者不必要的更改
- 百万级数据分页查询优化#
纯扫表:记录主键游标,记录上次最大主键Id,从该Id处开始扫
1
select * from t where id > max_id limit 100;
不记录游标只根据主键扫库, 不带where条件, 主键覆盖索引 + 子查询
1
select * from t where id in (select id from usertb limit 7000000,100);
带where条件,联合覆盖索引 key(type, id) + 子查询
1
select * from t where id in (select id from usertb where type=1 limit 7000000,100);
带where和orderby条件,联合覆盖索引key(a, b) + 子查询
1
select * from t where id in (select id from usertb where a=1 order by b limit 7000000,100);
尽量保证不要出现大的offset,加一些条件过滤一,不应该使用limit跳过已查询到的数据,offset做无用功。实际工程中,要避免出现大页码的情况,尽量引导用户做条件过滤。
mysql隔离级别#
- MVCC, 什么是快照读,什么是当前读#
快照读: 即普通SELECT语句,既然是快照读,故 SELECT 的时候,会生成一个快照。
生成快照的时机:事务中第一次调用SELECT语句的时候才会生成快照,在此之前事务中执行的update、insert、delete操作都不会生成快照。
不同事务隔离级别下,快照读的区别:
READ COMMITTED 隔离级别下,每次读取都会重新生成一个快照,所以每次快照都是最新的,也因此事务中每次SELECT也可以看到其它已commit事务所作的更改;
REPEATED READ 隔离级别下,快照会在事务中第一次SELECT语句执行时生成,只有在本事务中对数据进行更改才会更新快照,因此,只有第一次SELECT之前其它已提交事务所作的更改你可以看到,但是如果已执行了SELECT,那么其它事务commit数据,你SELECT是看不到的。
RC的本质:每一条SELECT都可以看到其他已经提交的事务对数据的修改,只要事务提交,其结果都可见,与事务开始的先后顺序无关。
RR的本质:第一条SELECT生成ReadView前,已经提交的事务的修改可见。
- 什么是当前读#
https://mp.weixin.qq.com/s/w1DwsDDSxKfmFxcLOgG3Dw
- mysql数据库事务隔离级别,分別解決什么问题,next-key锁原理、如何解决幻读?#
READ-UNCOMMITTED(未提交读): 可能会导致脏读、幻读或不可重复读
READ-COMMITTED(提交读): 可以阻止脏读,但是幻读或不可重复读仍有可能发生
REPEATABLE-READ(可重复读,mysql默认隔离级别): 可以阻止脏读和不可重复读,幻读通过mvcc解决了快照读,next-key锁解决了当前读
SERIALIZABLE(串行化读): 该级别可以防止脏读、不可重复读以及幻读
- RR RC区别#
区别就在于rr解决了不可重复读和幻读,怎么解决的,通过MVCC和next-key锁.
不可重复读:rc级别下的mvcc总是读取数据行的最新快照,而rr级别下的mvcc,会在事务第一次select的时候,为数据行生成一个快照,后面每次都读这个快照,除非自己更新,所以rr下是可重复读,别的事务提交也无法影响你的事务。
幻读:快照读下rr级别不会出现幻读,因为rr级别的mvcc读的是事务第一次读取时的快照;在当前读下rr级别使用了next-key锁(临键锁),临键锁包括行锁+间隙锁, 来避免两个当前读时有其它事务插入数据,所以当前读使用next-key锁解决的幻读。 最后备注下:如果是先快照读再当前读,影响行数不一致是否属于幻读,是有争议的但大多认为并不是幻读。
RC的本质:每一条SELECT都可以看到其他已经提交的事务对数据的修改,只要事务提交,其结果都可见,与事务开始的先后顺序无关。
RR的本质:第一条SELECT生成ReadView前,已经提交的事务的修改可见。
mysql其他#
- 分库分表#
根据userid取模做的分库分表
两个场景,业务解耦垂直拆分,读写性能瓶颈做水平拆分。
- 垂直切分
业务维度切分,解耦
- 水平切分
读写性能遇到瓶颈,分库分表
- mysql的乐观锁、悲观锁实现#
MySQL乐观锁的实现完全是逻辑的,也就是自己去实现。 比如给每条数据附带版本号或者timestamp。更新引起数据的版本号改变,两次select判断版本号是否一致可以判断是否发生改变
MySQL悲观锁的实现需要借助于MySQL的锁机制。
行锁
常见的增删改(INSERT、DELETE、UPDATE)语句会自动对操作的数据行加写锁,查询的时候也可以明确指定锁的类型,SELECT … LOCK IN SHARE MODE 语句加的是读锁,SELECT … FOR UPDATE 语句加的是写锁
行锁的实现方式
1) Record lock 锁记录
2) Gap lock 锁两个记录之间的 GAP,防止记录插入
3) Next-key lock 锁一条记录及其之前的间隙
- 主从延迟怎么办#
主从延迟的原因:
主库写入数据并且生成binlog文件, 从库异步读取更新
解决方案:
一、更新操作,做SQL优化,减少批量更新操作
二、查询场景,
- 强制读主,对主库压力大,谨慎使用
- 延迟读从, 将要更新的key先放到一个本地延迟队列中,做延迟处理。
- 聚合表, 如果是1:1的两张数据,可以先订阅更新到一张聚合表,再订阅聚合表的binlog
- 订阅全部从库的binlog, todo
- binlog、redolog、undolog#
binlog 一致性。用于主从复制和指定时间范围的数据恢复
redolog 保证持久性。log用于保证持久化,恢复在内存更新后,还没来得及刷到磁盘的数据
undolog 原子性。用于实现事务回滚和mvcc多版本并发控制